const
作用
- 修饰变量,说明该变量不可以被改变;
- 修饰指针,分为指向常量的指针和指针常量;
- 常量引用,经常用于形参类型,即避免了拷贝,又避免了函数对值的修改;
- 修饰成员函数,说明该成员函数内不能修改成员变量。
助记法宝
1、关键看const 修饰谁。
2、由于没有 const * 的运算,若出现 const * 的形式,则const实际上是修饰前面的。
使用
const 使用
// 类
class A
{
private:
const int a; // 常对象成员,只能在初始化列表赋值
public:
// 构造函数
A() : a(0) { };
A(int x) : a(x) { }; // 初始化列表
// const可用于对重载函数的区分
int getValue(); // 普通成员函数
int getValue() const; // 常成员函数,不得修改类中的任何数据成员的值
};
void function()
{
// 对象
A b; // 普通对象,可以调用全部成员函数
const A a; // 常对象,只能调用常成员函数、更新常成员变量
const A *p = &a; // 常指针
const A &q = a; // 常引用
// 指针
char greeting[] = "Hello";
char* p1 = greeting; // 指针变量,指向字符数组变量
const char* p2 = greeting; // 指针变量,指向字符数组常量
char* const p3 = greeting; // 常指针,指向字符数组变量
const char* const p4 = greeting; // 常指针,指向字符数组常量
}
// 函数
void function1(const int Var); // 传递过来的参数在函数内不可变
void function2(const char* Var); // 参数指针所指内容为常量
void function3(char* const Var); // 参数指针为常指针
void function4(const int& Var); // 引用参数在函数内为常量
// 函数返回值
const int function5(); // 返回一个常数
const int* function6(); // 返回一个指向常量的指针变量,使用:const int *p = function6();
int* const function7(); // 返回一个指向变量的常指针,使用:int* const p = function7();static
作用
-
函数内static局部变量:变量在程序初始化时被分配,直到程序退出前才被释放,也就是static是按照程序的生命周期来分配释放变量的,而不是变量自己的生命周期。多次调用,仅需一次初始化。
-
cpp内的static全局变量:只在cpp内有效。在不同的cpp文件中定义同名变量,不必担心命名冲突。保持变量内容的持久。
-
头文件内的static全局变量:在每个包含该头文件的cpp文件中都是独立的。不推荐使用。
-
static函数:仅在当前文件内有效。在不同的cpp文件中定义同名函数,不必担心命名冲突。对其它源文件隐藏。在现代C++中被无名namespace取代。
-
类的static数据成员:必须在class的外部初始化。
-
类的static函数:不能访问类的私有成员,只能访问类的static成员,不需要类的实例即可调用。可以继承和覆盖,但无法是虚函数。属于整个类而非类的对象,没有this指针。静态成员之间可以相互访问,包括静态成员函数访问静态数据成员和访问静态成员函数。非静态成员函数可以任意地访问静态成员函数和静态数据成员。静态成员函数不能访问非静态成员函数和非静态数据成员。
-
单例模式(Singleton)中使用static:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
使用
static 使用
// static.h
#include <iostream>
class A
{
public:
static int func(); // 只能调用静态成员
int func2();
public:
static int val;
private:
int val2 = 5;
static int val3; // 必须在类外进行初始化
};
struct X
{
private:
int i;
static int si;
public:
void set_i(int arg) { i = arg; }
static void set_si(int arg) { si = arg; }
void print_i()
{
std::cout << "Value of i = " << i << std::endl;
std::cout << "Again, value of i = " << this->i << std::endl;
}
static void print_si()
{
std::cout << "Value of si = " << si << std::endl;
// A static member function does not have a this pointer
//std::cout << "Again, value of si = " << this->si << std::endl; // error
}
};
class C
{
// A static member function cannot be declared with the keywords virtual, const, volatile, or const volatile.
// A static member function can access only the names of static members, enumerators, and nested types of the class in which it is declared.
static void f()
{
std::cout << "Here is i: " << i << std::endl;
}
static int i;
int j;
public:
C(int firstj) : j(firstj) {}
void printall();
};
class Singleton
{
public:
static Singleton &GetInstance()
{
static Singleton intance;
return intance;
}
~Singleton() = default;
private:
Singleton() = default;
Singleton(const Singleton &) = delete;
Singleton &operator=(const Singleton &) = delete;
};
// static.cpp
static size_t count_calls()
{
// 局部静态对象(local static object)在程序的执行路径第一次经过对象定义
// 语句时初始化,并且直到程序终止才被销毁,在此期间即使对象所在的函数结
// 束执行也不会对它有影响。
static size_t ctr = 0; // 调用结束后,这个值仍然有效
return ++ctr;
}
int test_static_1()
{
for (int i = 0; i < 10; ++i)
{
fprintf(stdout, "ctr: %d\n", count_calls());
}
return 0;
}
/////////////////////////////////////////////////////////////
int A::val = 10;
int A::val3 = 15;
int A::func()
{
return ++val3;
}
int A::func2()
{
return (val3 + val2 + func());
}
int test_static_2()
{
fprintf(stdout, "A::val: %d\n", A::val);
for (int i = 0; i < 5; ++i)
fprintf(stdout, "A::func: %d\n", A::func());
A a;
fprintf(stdout, "a.func2: %d\n", a.func2());
return 0;
}
////////////////////////////////////////////////////////////////
static int xx = 5;
int test_static_3()
{
fprintf(stdout, "xx: %d\n", xx);
return 0;
}
///////////////////////////////////////////////////////////////////
// reference: https://www.ibm.com/support/knowledgecenter/en/SSLTBW_2.3.0/com.ibm.zos.v2r3.cbclx01/cplr039.htm
int X::si = 77; // Initialize static data member
int test_static_4()
{
X xobj;
xobj.set_i(11);
xobj.print_i();
// static data members and functions belong to the class and
// can be accessed without using an object of class X
X::print_si();
X::set_si(22);
X::print_si();
return 0;
}
//////////////////////////////////////////////////////////
// reference: https://www.ibm.com/support/knowledgecenter/en/SSLTBW_2.3.0/com.ibm.zos.v2r3.cbclx01/cplr039.htm
void C::printall()
{
std::cout << "Here is j: " << this->j << std::endl;
// You can call a static member function using the this pointer of a nonstatic member function
this->f();
}
int C::i = 3;
int test_static_5()
{
C obj_C(2);
obj_C.printall();
return 0;
}
/////////////////////////////////////////////////////////
// reference: https://msdn.microsoft.com/en-us/library/y5f6w579.aspx
void showstat(int curr)
{
static int nStatic; // Value of nStatic is retained between each function call
nStatic += curr;
std::cout << "nStatic is " << nStatic << std::endl;
}
int test_static_6()
{
for (int i = 0; i < 5; i++)
showstat(i);
return 0;
}
int test_static_7()
{
Singleton &sgn1 = Singleton::Instance();
Singleton &sgn2 = Singleton::Instance();
if (&sgn1 == &sgn2)
std::cout << "ok" << std::endl;
else
std::cout << "no" << std::endl;
return 0;
}this 指针
this指针是一个隐含于每一个非静态成员函数中的特殊指针。它指向调用该成员函数的那个对象。- 当对一个对象调用成员函数时,编译程序先将对象的地址赋给
this指针,然后调用成员函数,每次成员函数存取数据成员时,都隐式使用this指针。 - 当一个成员函数被调用时,自动向它传递一个隐含的参数,该参数是一个指向这个成员函数所在的对象的指针。
this指针被隐含地声明为:ClassName *const this,这意味着不能给this指针赋值;在ClassName类的const成员函数中,this指针的类型为:const ClassName* const,这说明不能对this指针所指向的这种对象是不可修改的(即不能对这种对象的数据成员进行赋值操作);this并不是一个常规变量,而是个右值,所以不能取得this的地址(不能&this)。- 在以下场景中,经常需要显式引用
this指针:- 为实现对象的链式引用;
- 为避免对同一对象进行赋值操作;
- 在实现一些数据结构时,如
list。
inline 内联函数
特征
- 相当于把内联函数里面的内容写在调用内联函数处;
- 相当于不用执行进入函数的步骤,直接执行函数体;
- 相当于宏,却比宏多了类型检查,真正具有函数特性;
- 编译器一般不内联包含循环、递归、switch 等复杂操作的内联函数;
- 在类声明中定义的函数,除了虚函数的其他函数都会自动隐式地当成内联函数。
使用
inline 使用
// 声明1(加 inline,建议使用)
inline int functionName(int first, int secend,...);
// 声明2(不加 inline)
int functionName(int first, int secend,...);
// 定义
inline int functionName(int first, int secend,...) {/****/};
// 类内定义,隐式内联
class A {
int doA() { return 0; } // 隐式内联
}
// 类外定义,需要显式内联
class A {
int doA();
}
inline int A::doA() { return 0; } // 需要显式内联编译器对 inline 函数的处理步骤
- 将 inline 函数体复制到 inline 函数调用点处;
- 为所用 inline 函数中的局部变量分配内存空间;
- 将 inline 函数的的输入参数和返回值映射到调用方法的局部变量空间中;
- 如果 inline 函数有多个返回点,将其转变为 inline 函数代码块末尾的分支(使用 GOTO)。
优缺点
优点
- 内联函数同宏函数一样将在被调用处进行代码展开,省去了参数压栈、栈帧开辟与回收,结果返回等,从而提高程序运行速度。
- 内联函数相比宏函数来说,在代码展开时,会做安全检查或自动类型转换(同普通函数),而宏定义则不会。
- 在类中声明同时定义的成员函数,自动转化为内联函数,因此内联函数可以访问类的成员变量,宏定义则不能。
- 内联函数在运行时可调试,而宏定义不可以。
缺点
- 代码膨胀。内联是以代码膨胀(复制)为代价,消除函数调用带来的开销。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
- inline 函数无法随着函数库升级而升级。inline函数的改变需要重新编译,不像 non-inline 可以直接链接。
- 是否内联,程序员不可控。内联函数只是对编译器的建议,是否对函数内联,决定权在于编译器。
虚函数(virtual)可以是内联函数(inline)吗?
Are "inline virtual" member functions ever actually "inlined"?
- 虚函数可以是内联函数,内联是可以修饰虚函数的,但是当虚函数表现多态性的时候不能内联。
- 内联是在编译器建议编译器内联,而虚函数的多态性在运行期,编译器无法知道运行期调用哪个代码,因此虚函数表现为多态性时(运行期)不可以内联。
inline virtual唯一可以内联的时候是:编译器知道所调用的对象是哪个类(如Base::who()),这只有在编译器具有实际对象而不是对象的指针或引用时才会发生。
虚函数内联使用
#include <iostream>
using namespace std;
class Base
{
public:
inline virtual void who()
{
cout << "I am Base\n";
}
virtual ~Base() {}
};
class Derived : public Base
{
public:
inline void who() // 不写inline时隐式内联
{
cout << "I am Derived\n";
}
};
int main()
{
// 此处的虚函数 who(),是通过类(Base)的具体对象(b)来调用的,编译期间就能确定了,所以它可以是内联的,但最终是否内联取决于编译器。
Base b;
b.who();
// 此处的虚函数是通过指针调用的,呈现多态性,需要在运行时期间才能确定,所以不能为内联。
Base *ptr = new Derived();
ptr->who();
// 因为Base有虚析构函数(virtual ~Base() {})
// 所以 delete 时,会先调用派生类(Derived)析构函数,再调用基类(Base)析构函数,防止内存泄漏。
delete ptr;
ptr = nullptr;
// system("pause");
return 0;
}volatile
volatile int i = 10; - volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素(操作系统、硬件、其它线程等)更改。所以使用 volatile 告诉编译器不应对这样的对象进行优化。
- volatile 关键字声明的变量,每次访问时都必须从内存中取出值(没有被 volatile 修饰的变量,可能由于编译器的优化,从 CPU 寄存器中取值)
- const 可以是 volatile (如只读的状态寄存器)
- 指针可以是 volatile
assert()
断言,是宏,而非函数。assert 宏的原型定义在 <assert.h>(C)、<cassert>(C++)中,其作用是如果它的条件返回错误,则终止程序执行。可以通过定义 NDEBUG 来关闭 assert,但是需要在源代码的开头,include <assert.h> 之前。
assert() 使用
#define NDEBUG // 加上这行,则 assert 不可用
#include <assert.h>
assert( p != NULL ); // assert 不可用sizeof()
- sizeof 对数组,得到整个数组所占空间大小。
- sizeof 对指针,得到指针本身所占空间大小。
pragma pack(n)
设定结构体、联合以及类成员变量以 n 字节方式对齐
pragma pack(n) 使用
#pragma pack(push) // 保存对齐状态
#pragma pack(4) // 设定为 4 字节对齐
struct test
{
char m1;
double m4;
int m3;
};
#pragma pack(pop) // 恢复对齐状态位域
Bit mode: 2; // mode 占 2 位类可以将其(非静态)数据成员定义为位域(bit-field),在一个位域中含有一定数量的二进制位。当一个程序需要向其他程序或硬件设备传递二进制数据时,通常会用到位域。
- 位域在内存中的布局是与机器有关的
- 位域的类型必须是整型或枚举类型,带符号类型中的位域的行为将因具体实现而定
- 取地址运算符(&)不能作用于位域,任何指针都无法指向类的位域
extern "C"
- 被 extern 限定的函数或变量是 extern 类型的
- 被
extern "C"修饰的变量和函数是按照 C 语言方式编译和链接的
extern "C" 的作用是让 C++ 编译器将 extern "C" 声明的代码当作 C 语言代码处理,可以避免 C++ 因符号修饰导致代码不能和C语言库中的符号进行链接的问题。
extern "C" 使用
#ifdef __cplusplus
extern "C" {
#endif
void *memset(void *, int, size_t);
#ifdef __cplusplus
}
#endifstruct 和 typedef struct
C 中
// c
typedef struct Student {
int age;
} S;等价于
// c
struct Student {
int age;
};
typedef struct Student S;此时 S 等价于 struct Student,但两个标识符名称空间不相同。
另外还可以定义与 struct Student 不冲突的 void Student() {}。
C++ 中
由于编译器定位符号的规则(搜索规则)改变,导致不同于C语言。
一、如果在类标识符空间定义了 struct Student {...};,使用 Student me; 时,编译器将搜索全局标识符表,Student 未找到,则在类标识符内搜索。
即表现为可以使用 Student 也可以使用 struct Student,如下:
// cpp
struct Student {
int age;
};
void f( Student me ); // 正确,"struct" 关键字可省略二、若定义了与 Student 同名函数之后,则 Student 只代表函数,不代表结构体,如下:
typedef struct Student {
int age;
} S;
void Student() {} // 正确,定义后 "Student" 只代表此函数
//void S() {} // 错误,符号 "S" 已经被定义为一个 "struct Student" 的别名
int main() {
Student();
struct Student me; // 或者 "S me";
return 0;
}C++ 中 struct 和 class
总的来说,struct 更适合看成是一个数据结构的实现体,class 更适合看成是一个对象的实现体。
区别
最本质的一个区别就是默认的访问控制
- 默认的继承访问权限。struct 是 public 的,class 是 private 的。
- struct 作为数据结构的实现体,它默认的数据访问控制是 public 的,而 class 作为对象的实现体,它默认的成员变量访问控制是 private 的。
union 联合
联合(union)是一种节省空间的特殊的类,一个 union 可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当某个成员被赋值后其他成员变为未定义状态。联合有如下特点:
- 默认访问控制符为 public
- 可以含有构造函数、析构函数
- 不能含有引用类型的成员
- 不能继承自其他类,不能作为基类
- 不能含有虚函数
- 匿名 union 在定义所在作用域可直接访问 union 成员
- 匿名 union 不能包含 protected 成员或 private 成员
- 全局匿名联合必须是静态(static)的
union 使用
#include<iostream>
union UnionTest {
UnionTest() : i(10) {};
int i;
double d;
};
static union {
int i;
double d;
};
int main() {
UnionTest u;
union {
int i;
double d;
};
std::cout << u.i << std::endl; // 输出 UnionTest 联合的 10
::i = 20;
std::cout << ::i << std::endl; // 输出全局静态匿名联合的 20
i = 30;
std::cout << i << std::endl; // 输出局部匿名联合的 30
return 0;
}C 实现 C++ 类
explicit(显式)关键字
- explicit 修饰构造函数时,可以防止隐式转换和复制初始化
- explicit 修饰转换函数时,可以防止隐式转换,但 按语境转换 除外
explicit 使用
struct A
{
A(int) { }
operator bool() const { return true; }
};
struct B
{
explicit B(int) {}
explicit operator bool() const { return true; }
};
void doA(A a) {}
void doB(B b) {}
int main()
{
A a1(1); // OK:直接初始化
A a2 = 1; // OK:复制初始化
A a3{ 1 }; // OK:直接列表初始化
A a4 = { 1 }; // OK:复制列表初始化
A a5 = (A)1; // OK:允许 static_cast 的显式转换
doA(1); // OK:允许从 int 到 A 的隐式转换
if (a1); // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a6(a1); // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a7 = a1; // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a8 = static_cast<bool>(a1); // OK :static_cast 进行直接初始化
B b1(1); // OK:直接初始化
B b2 = 1; // 错误:被 explicit 修饰构造函数的对象不可以复制初始化
B b3{ 1 }; // OK:直接列表初始化
B b4 = { 1 }; // 错误:被 explicit 修饰构造函数的对象不可以复制列表初始化
B b5 = (B)1; // OK:允许 static_cast 的显式转换
doB(1); // 错误:被 explicit 修饰构造函数的对象不可以从 int 到 B 的隐式转换
if (b1); // OK:被 explicit 修饰转换函数 B::operator bool() 的对象可以从 B 到 bool 的按语境转换
bool b6(b1); // OK:被 explicit 修饰转换函数 B::operator bool() 的对象可以从 B 到 bool 的按语境转换
bool b7 = b1; // 错误:被 explicit 修饰转换函数 B::operator bool() 的对象不可以隐式转换
bool b8 = static_cast<bool>(b1); // OK:static_cast 进行直接初始化
return 0;
}friend 友元类和友元函数
- 能访问私有成员
- 破坏封装性
- 友元关系不可传递
- 友元关系的单向性
- 友元声明的形式及数量不受限制
using
using 声明
一条 using 声明 语句一次只引入命名空间的一个成员。它使得我们可以清楚知道程序中所引用的到底是哪个名字。如:
using namespace_name::name;构造函数的 using 声明
在 C++11 中,派生类能够重用其直接基类定义的构造函数。
class Derived : Base {
public:
using Base::Base;
/* ... */
};如上 using 声明,对于基类的每个构造函数,编译器都生成一个与之对应(形参列表完全相同)的派生类构造函数。生成如下类型构造函数:
derived(parms) : base(args) { }using 指示
using 指示 使得某个特定命名空间中所有名字都可见,这样我们就无需再为它们添加任何前缀限定符了。如:
using namespace_name name;尽量少使用 using 指示 污染命名空间
一般说来,使用 using 命令比使用 using 编译命令更安全,这是由于它只导入了指定的名称。如果该名称与局部名称发生冲突,编译器将发出指示。using编译命令导入所有的名称,包括可能并不需要的名称。如果与局部名称发生冲突,则局部名称将覆盖名称空间版本,而编译器并不会发出警告。另外,名称空间的开放性意味着名称空间的名称可能分散在多个地方,这使得难以准确知道添加了哪些名称。
using 使用
尽量少使用 using 指示
using namespace std;应该多使用 using 声明
int x;
std::cin >> x ;
std::cout << x << std::endl;或者
using std::cin;
using std::cout;
using std::endl;
int x;
cin >> x;
cout << x << endl;:: 范围解析运算符
分类
- 全局作用域符(
::name):用于类型名称(类、类成员、成员函数、变量等)前,表示作用域为全局命名空间 - 类作用域符(
class::name):用于表示指定类型的作用域范围是具体某个类的 - 命名空间作用域符(
namespace::name):用于表示指定类型的作用域范围是具体某个命名空间的
:: 使用
int count = 0; // 全局(::)的 count
class A {
public:
static int count; // 类 A 的 count(A::count)
};
int main() {
::count = 1; // 设置全局的 count 的值为 1
A::count = 2; // 设置类 A 的 count 为 2
int count = 0; // 局部的 count
count = 3; // 设置局部的 count 的值为 3
return 0;
}enum 枚举类型
限定作用域的枚举类型
enum class open_modes { input, output, append };不限定作用域的枚举类型
enum color { red, yellow, green };
enum { floatPrec = 6, doublePrec = 10 };引用
左值引用
常规引用,一般表示对象的身份。
右值引用
右值引用就是必须绑定到右值(一个临时对象、将要销毁的对象)的引用,一般表示对象的值。
右值引用可实现转移语义(Move Sementics)和精确传递(Perfect Forwarding),它的主要目的有两个方面:
- 消除两个对象交互时不必要的对象拷贝,节省运算存储资源,提高效率。
- 能够更简洁明确地定义泛型函数。
引用折叠
X& &、X& &&、X&& &可折叠成X&X&& &&可折叠成X&&
宏
- 宏定义可以实现类似于函数的功能,但是它终归不是函数,而宏定义中括弧中的“参数”也不是真的参数,在宏展开的时候对 “参数” 进行的是一对一的替换。
成员初始化列表
好处
- 更高效:少了一次调用默认构造函数的过程。
- 有些场合必须要用初始化列表:
- 常量成员,因为常量只能初始化不能赋值,所以必须放在初始化列表里面
- 引用类型,引用必须在定义的时候初始化,并且不能重新赋值,所以也要写在初始化列表里面
- 没有默认构造函数的类类型,因为使用初始化列表可以不必调用默认构造函数来初始化,而是直接调用拷贝构造函数初始化。
面向对象
面向对象程序设计(Object-oriented programming,OOP)是种具有对象概念的程序编程典范,同时也是一种程序开发的抽象方针。
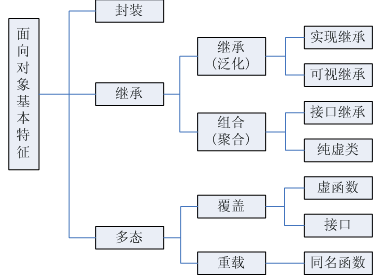
面向对象三大特征 —— 封装、继承、多态
封装
把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。关键字:public, protected, private。不写默认为 private。
public成员:可以被任意实体访问protected成员:只允许被子类及本类的成员函数访问private成员:只允许被本类的成员函数访问
继承
- 基类(父类)——> 派生类(子类)
多态
- 多态,即多种状态(形态)。简单来说,我们可以将多态定义为消息以多种形式显示的能力。
- 多态是以封装和继承为基础的。
- C++ 多态分类及实现:
- 重载多态(Ad-hoc Polymorphism,编译期):函数重载、运算符重载。如有两个或多个函数名相同的函数,但是函数的形参列表不同。
- 子类型多态(Subtype Polymorphism,运行期):虚函数。
- 参数多态性(Parametric Polymorphism,编译期):类模板、函数模板。
- 强制多态(Coercion Polymorphism,编译期/运行期):基本类型转换、自定义类型转换
// 重载多态
int add(int a, int b) {
return a + b;
}
std::string add(const char *a, const char *b) {
std::string result(a);
result += b;
return result;
}
// 子类型多态
// 参数多态性
template <class T>
T max(T a, T b) {
return a > b ? a : b;
}
std::cout << ::max(9, 5) << std::endl; // 9
std::string foo("foo"), bar("bar");
std::cout << ::max(foo, bar) << std::endl; // "foo"
// 强制多态
class A
{
int foo;
public:
A(int ffoo) : foo(ffoo) {}
void giggidy() { std::cout << foo << std::endl; }
};
void moo(A a)
{
a.giggidy();
}
int main()
{
moo(55); // prints 55
}静态多态(编译期/早绑定)
函数重载
class A
{
public:
void do(int a);
void do(int a, int b);
};动态多态(运行期期/晚绑定)
- 虚函数:用 virtual 修饰成员函数,使其成为虚函数
注意:
- 普通函数(非类成员函数)不能是虚函数
- 静态函数(static)不能是虚函数
- 构造函数不能是虚函数(因为在调用构造函数时,虚表指针并没有在对象的内存空间中,必须要构造函数调用完成后才会形成虚表指针)
- 内联函数不能是表现多态性时的虚函数,解释见:虚函数(virtual)可以是内联函数(inline)吗?
动态多态使用
class Shape // 形状类
{
public:
virtual double calcArea()
{
...
}
virtual ~Shape();
};
class Circle : public Shape // 圆形类
{
public:
virtual double calcArea();
...
};
class Rect : public Shape // 矩形类
{
public:
virtual double calcArea();
...
};
int main()
{
Shape * shape1 = new Circle(4.0);
Shape * shape2 = new Rect(5.0, 6.0);
shape1->calcArea(); // 调用圆形类里面的方法
shape2->calcArea(); // 调用矩形类里面的方法
delete shape1;
shape1 = nullptr;
delete shape2;
shape2 = nullptr;
return 0;
}虚析构函数
虚析构函数是为了解决基类的指针指向派生类对象,并用基类的指针删除派生类对象。
虚析构函数使用
class Shape
{
public:
Shape(); // 构造函数不能是虚函数
virtual double calcArea();
virtual ~Shape(); // 虚析构函数
};
class Circle : public Shape // 圆形类
{
public:
virtual double calcArea();
...
};
int main()
{
Shape * shape1 = new Circle(4.0);
shape1->calcArea();
delete shape1; // 因为Shape有虚析构函数,所以delete释放内存时,先调用子类析构函数,再调用基类析构函数,防止内存泄漏。
shape1 = NULL;
return 0;
}纯虚函数
纯虚函数是一种特殊的虚函数,在基类中不能对虚函数给出有意义的实现,而把它声明为纯虚函数,它的实现留给该基类的派生类去做。
virtual int A() = 0;虚函数、纯虚函数
- 类里如果声明了虚函数,这个函数是实现的,哪怕是空实现,它的作用就是为了能让这个函数在它的子类里面可以被覆盖,这样的话,这样编译器就可以使用后期绑定来达到多态了。纯虚函数只是一个接口,是个函数的声明而已,它要留到子类里去实现。
- 虚函数在子类里面也可以不重载的;但纯虚函数必须在子类去实现。
- 虚函数的类用于 “实作继承”,继承接口的同时也继承了父类的实现。当然大家也可以完成自己的实现。纯虚函数关注的是接口的统一性,实现由子类完成。
- 带纯虚函数的类叫抽象类,这种类不能直接生成对象,而只有被继承,并重写其虚函数后,才能使用。抽象类和大家口头常说的虚基类还是有区别的,在 C# 中用 abstract 定义抽象类,而在 C++ 中有抽象类的概念,但是没有这个关键字。抽象类被继承后,子类可以继续是抽象类,也可以是普通类,而虚基类,是含有纯虚函数的类,它如果被继承,那么子类就必须实现虚基类里面的所有纯虚函数,其子类不能是抽象类。
虚函数指针、虚函数表
- 虚函数指针:在含有虚函数类的对象中,指向虚函数表,在运行时确定。
- 虚函数表:在程序只读数据段(
.rodata section,见:目标文件存储结构),存放虚函数指针,如果派生类实现了基类的某个虚函数,则在虚表中覆盖原本基类的那个虚函数指针,在编译时根据类的声明创建。
虚继承
虚继承用于解决多继承条件下的菱形继承问题(浪费存储空间、存在二义性)。
底层实现原理与编译器相关,一般通过虚基类指针和虚基类表实现,每个虚继承的子类都有一个虚基类指针(占用一个指针的存储空间,4字节)和虚基类表(不占用类对象的存储空间)(需要强调的是,虚基类依旧会在子类里面存在拷贝,只是仅仅最多存在一份而已,并不是不在子类里面了);当虚继承的子类被当做父类继承时,虚基类指针也会被继承。
实际上,vbptr 指的是虚基类表指针(virtual base table pointer),该指针指向了一个虚基类表(virtual table),虚表中记录了虚基类与本类的偏移地址;通过偏移地址,这样就找到了虚基类成员,而虚继承也不用像普通多继承那样维持着公共基类(虚基类)的两份同样的拷贝,节省了存储空间。
虚继承、虚函数
- 相同之处:都利用了虚指针(均占用类的存储空间)和虚表(均不占用类的存储空间)
- 不同之处:
- 虚继承
- 虚基类依旧存在继承类中,只占用存储空间
- 虚基类表存储的是虚基类相对直接继承类的偏移
- 虚函数
- 虚函数不占用存储空间
- 虚函数表存储的是虚函数地址
- 虚继承
模板类、成员模板、虚函数
- 模板类中可以使用虚函数
- 一个类(无论是普通类还是类模板)的成员模板(本身是模板的成员函数)不能是虚函数
抽象类、接口类、聚合类
- 抽象类:含有纯虚函数的类
- 接口类:仅含有纯虚函数的抽象类
- 聚合类:用户可以直接访问其成员,并且具有特殊的初始化语法形式。满足如下特点:
- 所有成员都是 public
- 没有定义任何构造函数
- 没有类内初始化
- 没有基类,也没有 virtual 函数
C++ 空类默认产生成员函数
默认构造函数、默认拷贝构造函数、默认析构函数、默认赋值运算符 这四个是我们通常大都知道的。但是除了这四个,还有两个,那就是取址运算符和 取址运算符 const即总共有六个函数。代码示例:
class Empty
{
public:
Empty(); // 缺省构造函数
Empty(const Empty &); // 拷贝构造函数
~Empty(); // 析构函数
Empty& operator=(const Empty &); // 赋值运算符
Empty* operator&(); // 取址运算符
const Empty* operator&() const; // 取址运算符 const
};内存分配和管理
malloc、calloc、realloc、alloca
- malloc:申请指定字节数的内存。申请到的内存中的初始值不确定。
- calloc:为指定长度的对象,分配能容纳其指定个数的内存。申请到的内存的每一位(bit)都初始化为 0。
- realloc:更改以前分配的内存长度(增加或减少)。当增加长度时,可能需将以前分配区的内容移到另一个足够大的区域,而新增区域内的初始值则不确定。
- alloca:在栈上申请内存。程序在出栈的时候,会自动释放内存。但是需要注意的是,alloca 不具可移植性, 而且在没有传统堆栈的机器上很难实现。alloca 不宜使用在必须广泛移植的程序中。C99 中支持变长数组 (VLA),可以用来替代 alloca。
malloc、free
用于分配、释放内存
malloc、free 使用
申请内存,确认是否申请成功
char *str = (char*) malloc(100);
assert(str != nullptr);释放内存后指针置空
free(p);
p = nullptr;new、delete
- new / new[]:完成两件事,先底层调用 malloc 分配了内存,然后调用构造函数(创建对象)。
- delete/delete[]:也完成两件事,先调用析构函数(清理资源),然后底层调用 free 释放空间。
- new 在申请内存时会自动计算所需字节数,而 malloc 则需我们自己输入申请内存空间的字节数。
new、delete 使用
申请内存,确认是否申请成功
int main()
{
T* t = new T(); // 先内存分配 ,再构造函数
delete t; // 先析构函数,再内存释放
return 0;
}定位 new
定位 new(placement new)允许我们向 new 传递额外的地址参数,从而在预先指定的内存区域创建对象。
new (place_address) type
new (place_address) type (initializers)
new (place_address) type [size]
new (place_address) type [size] { braced initializer list }place_address是个指针initializers提供一个(可能为空的)以逗号分隔的初始值列表
#include <iostream>
using namespace std;
int main()
{
char *addr = new char[100];
char *p = nullptr;
p = new(addr)char;
*p = 'a';
cout << "addr address = " << (void*)addr << ", addr[0] = " << addr[0] << endl;
cout << "p address = " << (void*)p << ", p = " << *p << endl;
// addr address = 0x1011790, addr[0] = a
// p address = 0x1011790, p = a
return 0;
}delete this 合法吗?
Is it legal (and moral) for a member function to say delete this?
合法,但:
- 必须保证 this 对象是通过
new(不是new[]、不是 placement new、不是栈上、不是全局、不是其他对象成员)分配的 - 必须保证调用
delete this的成员函数是最后一个调用 this 的成员函数 - 必须保证成员函数的
delete this后面没有调用 this 了 - 必须保证
delete this后没有人使用了
如何定义一个只能在堆上(栈上)生成对象的类?
只能在堆上
方法:将析构函数设置为私有
class A
{
protected:
A(){}
~A(){}
public:
static A* create()
{
return new A();
}
void destory()
{
delete this;
}
};原因:C++ 是静态绑定语言,编译器管理栈上对象的生命周期,编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性。若析构函数不可访问,则不能在栈上创建对象。
只能在栈上
方法:将 new 和 delete 重载为私有
class A
{
private:
void* operator new(size_t t){} // 注意函数的第一个参数和返回值都是固定的
void operator delete(void* ptr){} // 重载了new就需要重载delete
public:
A(){}
~A(){}
};
原因:在堆上生成对象,使用 new 关键词操作,其过程分为两阶段:第一阶段,使用 new 在堆上寻找可用内存,分配给对象;第二阶段,调用构造函数生成对象。将 new 操作设置为私有,那么第一阶段就无法完成,就不能够在堆上生成对象。
强制类型转换运算符
static_cast
- 用于非多态类型的转换
- 不执行运行时类型检查(转换安全性不如 dynamic_cast)
- 通常用于转换数值数据类型(如 float -> int)
- 可以在整个类层次结构中移动指针,子类转化为父类安全(向上转换),父类转化为子类不安全(因为子类可能有不在父类的字段或方法)
向上转换是一种隐式转换。
dynamic_cast
- 用于多态类型的转换
- 执行行运行时类型检查
- 只适用于指针或引用
- 对不明确的指针的转换将失败(返回 nullptr),但不引发异常
- 可以在整个类层次结构中移动指针,包括向上转换、向下转换
const_cast
- 用于删除 const、volatile 和 __unaligned 特性(如将 const int 类型转换为 int 类型 )
reinterpret_cast
- 通过重新解释底层位模式在类型间转换。
- 滥用 reinterpret_cast 运算符可能很容易带来风险。 除非所需转换本身是低级别的,否则应使用其他强制转换运算符之一。
- 允许将任何指针转换为任何其他指针类型(如
char*到int*或One_class*到Unrelated_class*之类的转换,但其本身并不安全) - 也允许将任何整数类型转换为任何指针类型以及反向转换。
- reinterpret_cast 运算符不能丢掉 const、volatile 或 __unaligned 特性。
- reinterpret_cast 的一个实际用途是在哈希函数中,即,通过让两个不同的值几乎不以相同的索引结尾的方式将值映射到索引。
struct S1 { int a; } s1; int* p1 = reinterpret_cast<int*>(&s1); // p1 的值为“指向 s1.a 的指针”
bad_cast
- 由于强制转换为引用类型失败,dynamic_cast 运算符引发 bad_cast 异常。
bad_cast 使用
try {
Circle& ref_circle = dynamic_cast<Circle&>(ref_shape);
}
catch (bad_cast b) {
cout << "Caught: " << b.what();
} 运行时类型信息 (RTTI)
dynamic_cast
- 用于多态类型的转换
typeid
- typeid 运算符允许在运行时确定对象的类型
- type_id 返回一个 type_info 对象的引用
- 如果想通过基类的指针获得派生类的数据类型,基类必须带有虚函数
- 只能获取对象的实际类型
type_info
- type_info 类描述编译器在程序中生成的类型信息。 此类的对象可以有效存储指向类型的名称的指针。 type_info 类还可存储适合比较两个类型是否相等或比较其排列顺序的编码值。 类型的编码规则和排列顺序是未指定的,并且可能因程序而异。
- 头文件:
typeinfo
typeid、type_info 使用
class Flyable // 能飞的
{
public:
virtual void takeoff() = 0; // 起飞
virtual void land() = 0; // 降落
};
class Bird : public Flyable // 鸟
{
public:
void foraging() {...} // 觅食
virtual void takeoff() {...}
virtual void land() {...}
};
class Plane : public Flyable // 飞机
{
public:
void carry() {...} // 运输
virtual void take off() {...}
virtual void land() {...}
};
class type_info
{
public:
const char* name() const;
bool operator == (const type_info & rhs) const;
bool operator != (const type_info & rhs) const;
int before(const type_info & rhs) const;
virtual ~type_info();
private:
...
};
class doSomething(Flyable *obj) // 做些事情
{
obj->takeoff();
cout << typeid(*obj).name() << endl; // 输出传入对象类型("class Bird" or "class Plane")
if(typeid(*obj) == typeid(Bird)) // 判断对象类型
{
Bird *bird = dynamic_cast<Bird *>(obj); // 对象转化
bird->foraging();
}
obj->land();
};结构体成员偏移量
// C 风格
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
// C++ 风格
#define myoffsetof(s, m) (reinterpret_cast<size_t>(&(static_cast<s *>(nullptr)->m)))(TYPE )0,将 0 强制转换为 TYPE 型指针,记 p = (TYPE )0,p是指向TYPE的指针,它的值是0。那么 p->MEMBER 就是 MEMBER 这个元素了,而&(p->MEMBER)就是MENBER的地址,而基地址为0,这样就巧妙的转化为了TYPE中的偏移量。再把结果强制转换为size_t型的就OK了,size_t其实也就是int。
Effective C++
- 视 C++ 为一个语言联邦(C、Object-Oriented C++、Template C++、STL)
- 宁可以编译器替换预处理器(尽量以
const、enum、inline替换#define) - 尽可能使用 const
- 确定对象被使用前已先被初始化(构造时赋值(copy 构造函数)比 default 构造后赋值(copy assignment)效率高)
- 了解 C++ 默默编写并调用哪些函数(编译器暗自为 class 创建 default 构造函数、copy 构造函数、copy assignment 操作符、析构函数)
- 若不想使用编译器自动生成的函数,就应该明确拒绝(将不想使用的成员函数声明为 private,并且不予实现)
- 为多态基类声明 virtual 析构函数(如果 class 带有任何 virtual 函数,它就应该拥有一个 virtual 析构函数)
- 别让异常逃离析构函数(析构函数应该吞下不传播异常,或者结束程序,而不是吐出异常;如果要处理异常应该在非析构的普通函数处理)
- 绝不在构造和析构过程中调用 virtual 函数(因为这类调用从不下降至 derived class)
- 令
operator=返回一个reference to *this(用于连锁赋值) - 在
operator=中处理 “自我赋值” - 赋值对象时应确保复制 “对象内的所有成员变量” 及 “所有 base class 成分”(调用基类复制构造函数)
- 以对象管理资源(资源在构造函数获得,在析构函数释放,建议使用智能指针,资源取得时机便是初始化时机(Resource Acquisition Is Initialization,RAII))
- 在资源管理类中小心 copying 行为(普遍的 RAII class copying 行为是:抑制 copying、引用计数、深度拷贝、转移底部资源拥有权(类似 auto_ptr))
- 在资源管理类中提供对原始资源(raw resources)的访问(对原始资源的访问可能经过显式转换或隐式转换,一般而言显示转换比较安全,隐式转换对客户比较方便)
- 成对使用 new 和 delete 时要采取相同形式(
new中使用[]则delete [],new中不使用[]则delete) - 以独立语句将 newed 对象存储于(置入)智能指针(如果不这样做,可能会因为编译器优化,导致难以察觉的资源泄漏)
- 让接口容易被正确使用,不易被误用(促进正常使用的办法:接口的一致性、内置类型的行为兼容;阻止误用的办法:建立新类型,限制类型上的操作,约束对象值、消除客户的资源管理责任)
- 设计 class 犹如设计 type,需要考虑对象创建、销毁、初始化、赋值、值传递、合法值、继承关系、转换、一般化等等。
- 宁以 pass-by-reference-to-const 替换 pass-by-value (前者通常更高效、避免切割问题(slicing problem),但不适用于内置类型、STL迭代器、函数对象)
- 必须返回对象时,别妄想返回其 reference(绝不返回 pointer 或 reference 指向一个 local stack 对象,或返回 reference 指向一个 heap-allocated 对象,或返回 pointer 或 reference 指向一个 local static 对象而有可能同时需要多个这样的对象。)
- 将成员变量声明为 private(为了封装、一致性、对其读写精确控制等)
- 宁以 non-member、non-friend 替换 member 函数(可增加封装性、包裹弹性(packaging flexibility)、机能扩充性)
- 若所有参数(包括被this指针所指的那个隐喻参数)皆须要类型转换,请为此采用 non-member 函数
- 考虑写一个不抛异常的 swap 函数
- 尽可能延后变量定义式的出现时间(可增加程序清晰度并改善程序效率)
- 尽量少做转型动作(旧式:
(T)expression、T(expression);新式:const_cast<T>(expression)、dynamic_cast<T>(expression)、reinterpret_cast<T>(expression)、static_cast<T>(expression)、;尽量避免转型、注重效率避免 dynamic_casts、尽量设计成无需转型、可把转型封装成函数、宁可用新式转型) - 避免使用 handles(包括 引用、指针、迭代器)指向对象内部(以增加封装性、使 const 成员函数的行为更像 const、降低 “虚吊号码牌”(dangling handles,如悬空指针等)的可能性)
- 为 “异常安全” 而努力是值得的(异常安全函数(Exception-safe functions)即使发生异常也不会泄露资源或允许任何数据结构败坏,分为三种可能的保证:基本型、强列型、不抛异常型)
- 透彻了解 inlining 的里里外外(inlining 在大多数 C++ 程序中是编译期的行为;inline 函数是否真正 inline,取决于编译器;大部分编译器拒绝太过复杂(如带有循环或递归)的函数 inlining,而所有对 virtual 函数的调用(除非是最平淡无奇的)也都会使 inlining 落空;inline 造成的代码膨胀可能带来效率损失;inline 函数无法随着程序库的升级而升级)
- 将文件间的编译依存关系降至最低(如果使用 object references 或 object pointers 可以完成任务,就不要使用 objects;如果能过够,尽量以 class 声明式替换 class 定义式;为声明式和定义式提供不同的头文件)
- 确定你的 public 继承塑模出 is-a(是一种)关系(适用于 base classes 身上的每一件事情一定适用于 derived classes 身上,因为每一个 derived class 对象也都是一个 base class 对象)
- 避免遮掩继承而来的名字(可使用 using 声明式或转交函数(forwarding functions)来让被遮掩的名字再见天日)
- 区分接口继承和实现继承(在 public 继承之下,derived classes 总是继承 base class 的接口;pure virtual 函数只具体指定接口继承;非纯 impure virtual 函数具体指定接口继承及缺省实现继承;non-virtual 函数具体指定接口继承以及强制性实现继承)
- 考虑 virtual 函数以外的其他选择(如 Template Method 设计模式的 non-virtual interface(NVI)手法,将 virtual 函数替换为 “函数指针成员变量”,以
tr1::function成员变量替换 virtual 函数,将继承体系内的 virtual 函数替换为另一个继承体系内的 virtual 函数) - 绝不重新定义继承而来的 non-virtual 函数
- 绝不重新定义继承而来的缺省参数值,因为缺省参数值是静态绑定(statically bound),而 virtual 函数却是动态绑定(dynamically bound)
- 通过复合塑模 has-a(有一个)或 “根据某物实现出”(在应用域(application domain),复合意味 has-a(有一个);在实现域(implementation domain),复合意味着 is-implemented-in-terms-of(根据某物实现出))
- 明智而审慎地使用 private 继承(private 继承意味着 is-implemented-in-terms-of(根据某物实现出),尽可能使用复合,当 derived class 需要访问 protected base class 的成员,或需要重新定义继承而来的时候 virtual 函数,或需要 empty base 最优化时,才使用 private 继承)
- 明智而审慎地使用多重继承(多继承比单一继承复杂,可能导致新的歧义性,以及对 virtual 继承的需要,但确有正当用途,如 “public 继承某个 interface class” 和 “private 继承某个协助实现的 class”;virtual 继承可解决多继承下菱形继承的二义性问题,但会增加大小、速度、初始化及赋值的复杂度等等成本)
- 了解隐式接口和编译期多态(class 和 templates 都支持接口(interfaces)和多态(polymorphism);class 的接口是以签名为中心的显式的(explicit),多态则是通过 virtual 函数发生于运行期;template 的接口是奠基于有效表达式的隐式的(implicit),多态则是通过 template 具现化和函数重载解析(function overloading resolution)发生于编译期)
- 了解 typename 的双重意义(声明 template 类型参数是,前缀关键字 class 和 typename 的意义完全相同;请使用关键字 typename 标识嵌套从属类型名称,但不得在基类列(base class lists)或成员初值列(member initialization list)内以它作为 basee class 修饰符)
- 学习处理模板化基类内的名称(可在 derived class templates 内通过
this->指涉 base class templates 内的成员名称,或藉由一个明白写出的 “base class 资格修饰符” 完成) - 将与参数无关的代码抽离 templates(因类型模板参数(non-type template parameters)而造成代码膨胀往往可以通过函数参数或 class 成员变量替换 template 参数来消除;因类型参数(type parameters)而造成的代码膨胀往往可以通过让带有完全相同二进制表述(binary representations)的实现类型(instantiation types)共享实现码)
- 运用成员函数模板接受所有兼容类型(请使用成员函数模板(member function templates)生成 “可接受所有兼容类型” 的函数;声明 member templates 用于 “泛化 copy 构造” 或 “泛化 assignment 操作” 时还需要声明正常的 copy 构造函数和 copy assignment 操作符)
- 需要类型转换时请为模板定义非成员函数(当我们编写一个 class template,而它所提供之 “与此 template 相关的” 函数支持 “所有参数之隐式类型转换” 时,请将那些函数定义为 “class template 内部的 friend 函数”)
- 请使用 traits classes 表现类型信息(traits classes 通过 templates 和 “templates 特化” 使得 “类型相关信息” 在编译期可用,通过重载技术(overloading)实现在编译期对类型执行 if...else 测试)
- 认识 template 元编程(模板元编程(TMP,template metaprogramming)可将工作由运行期移往编译期,因此得以实现早期错误侦测和更高的执行效率;TMP 可被用来生成 “给予政策选择组合”(based on combinations of policy choices)的客户定制代码,也可用来避免生成对某些特殊类型并不适合的代码)
- 了解 new-handler 的行为(set_new_handler 允许客户指定一个在内存分配无法获得满足时被调用的函数;nothrow new 是一个颇具局限的工具,因为它只适用于内存分配(operator new),后继的构造函数调用还是可能抛出异常)
- 了解 new 和 delete 的合理替换时机(为了检测运用错误、收集动态分配内存之使用统计信息、增加分配和归还速度、降低缺省内存管理器带来的空间额外开销、弥补缺省分配器中的非最佳齐位、将相关对象成簇集中、获得非传统的行为)
- 编写 new 和 delete 时需固守常规(operator new 应该内涵一个无穷循环,并在其中尝试分配内存,如果它无法满足内存需求,就应该调用 new-handler,它也应该有能力处理 0 bytes 申请,class 专属版本则还应该处理 “比正确大小更大的(错误)申请”;operator delete 应该在收到 null 指针时不做任何事,class 专属版本则还应该处理 “比正确大小更大的(错误)申请”)
- 写了 placement new 也要写 placement delete(当你写一个 placement operator new,请确定也写出了对应的 placement operator delete,否则可能会发生隐微而时断时续的内存泄漏;当你声明 placement new 和 placement delete,请确定不要无意识(非故意)地遮掩了它们地正常版本)
- 不要轻忽编译器的警告
- 让自己熟悉包括 TR1 在内的标准程序库(TR1,C++ Technical Report 1,C++11 标准的草稿文件)
- 让自己熟悉 Boost(准标准库)
Google C++ Style Guide
英文:Google C++ Style Guide
中文:C++ 风格指南
一张图总结Google C++编程规范(Google C++ Style Guide)
C++有哪些内存区
- 内存栈区:存放局部变量名;
- 内存堆区:存放new或者malloc出来的对象;
- 常数区:存放局部变量或者全局变量的值;
- 静态区:用于存放全局变量或者静态变量;
- 代码区:二进制代码。
C/C++程序内存的各种变量存储区域和各个区域详解
运算符重载前++与后++
[返回类型] operator++() ; // 如果参数列表里什么都没有,那么就是重载前置自增运算符
[返回类型] operator++(int) ; // 如果参数列表里有一个参数,不管是什么类型,那么就是重载后置自增运算符,这个类型是int,double或者是其他都无所谓,它的目的仅仅是告诉编译器这里是有参数的,如果有参数,编译器就知道这里是重载后置运算符。
函数指针与指针函数
指针函数的本质是一个函数,只不过其返回值是一个指针类型的变量,函数指针的本质是一个变量,该变量的内容指向一个函数。
- 指针函数:
int* f(int a, int b); // 返回值为int *,指针类型的返回值 - 函数指针:
int (*f)(int a, int b); // 该函数指针f是一个指向返回值为整型,有两个参数并且两个参数的类型都是整型的函数
sizeof(class) 原则
- 类的大小为类的非静态成员数据的类型大小之和,也就是说静态成员数据不作考虑。
- 普通成员函数与sizeof无关。
- 虚函数由于要维护在虚函数表,所以要占据一个指针大小,也就是4字节。
- 类的总大小也遵守类似class字节对齐的,调整规则。
- 不占空间的有:普通函数,静态数据成员,静态成员函数。
- 无论多少个,只相当于一个所占的空间:虚函数。
- 空类占1个字节。
- 既有字符型又有整型,要考虑字节对齐。
- 普通数据成员、const数据成员占空间;静态成员不占空间。