进程与线程
对于有线程系统:
- 进程是资源分配的独立单位
- 线程是资源调度的独立单位
对于无线程系统:
- 进程是资源调度、分配的独立单位
进程之间的通信方式以及优缺点
- 管道(PIPE)
- 有名管道:一种半双工的通信方式,它允许无亲缘关系进程间的通信
- 优点:可以实现任意关系的进程间的通信
- 缺点:长期存于系统中,使用不当容易出错;缓冲区有限
- 无名管道:一种半双工的通信方式,只能在具有亲缘关系的进程间使用(父子进程)
- 优点:简单方便
- 缺点:局限于单向通信;只能创建在它的进程以及其有亲缘关系的进程之间;缓冲区有限
- 有名管道:一种半双工的通信方式,它允许无亲缘关系进程间的通信
- 信号量(Semaphore):一个计数器,可以用来控制多个线程对共享资源的访问
- 优点:可以同步进程
- 缺点:信号量有限
- 信号(Signal):一种比较复杂的通信方式,用于通知接收进程某个事件已经发生
- 消息队列(Message Queue):是消息的链表,存放在内核中并由消息队列标识符标识
- 优点:可以实现任意进程间的通信,并通过系统调用函数来实现消息发送和接收之间的同步,无需考虑同步问题,方便
- 缺点:信息的复制需要额外消耗 CPU 的时间,不适宜于信息量大或操作频繁的场合
- 共享内存(Shared Memory):映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问
- 优点:无须复制,快捷,信息量大
- 缺点:通信是通过将共享空间缓冲区直接附加到进程的虚拟地址空间中来实现的,因此进程间的读写操作的同步问题;利用内存缓冲区直接交换信息,内存的实体存在于计算机中,只能同一个计算机系统中的诸多进程共享,不方便网络通信
- 套接字(Socket):可用于不同及其间的进程通信
- 优点:传输数据为字节级,传输数据可自定义,数据量小效率高;传输数据时间短,性能高;适合于客户端和服务器端之间信息实时交互;可以加密,数据安全性强
- 缺点:需对传输的数据进行解析,转化成应用级的数据。
线程之间的通信方式
- 锁机制:包括互斥锁/量(mutex)、读写锁(reader-writer lock)、自旋锁(spin lock)、条件变量(condition)
- 互斥锁/量(mutex):提供了以排他方式防止数据结构被并发修改的方法。
- 读写锁(reader-writer lock):允许多个线程同时读共享数据,而对写操作是互斥的。
- 自旋锁(spin lock)与互斥锁类似,都是为了保护共享资源。互斥锁是当资源被占用,申请者进入睡眠状态;而自旋锁则循环检测保持着是否已经释放锁。
- 条件变量(condition):可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
- 信号量机制(Semaphore)
- 无名线程信号量
- 命名线程信号量
- 信号机制(Signal):类似进程间的信号处理
- 屏障(barrier):屏障允许每个线程等待,直到所有的合作线程都达到某一点,然后从该点继续执行。
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制
进程之间的通信方式以及优缺点来源于:进程线程面试题总结
进程之间私有和共享的资源
- 私有:地址空间、堆、全局变量、栈、寄存器
- 共享:代码段,公共数据,进程目录,进程 ID
线程之间私有和共享的资源
- 私有:线程栈,寄存器,程序寄存器
- 共享:堆,地址空间,全局变量,静态变量
多进程与多线程间的对比、优劣与选择
对比
| 对比维度 | 多进程 | 多线程 | 总结 |
|---|---|---|---|
| 数据共享、同步 | 数据共享复杂,需要用 IPC;数据是分开的,同步简单 | 因为共享进程数据,数据共享简单,但也是因为这个原因导致同步复杂 | 各有优势 |
| 内存、CPU | 占用内存多,切换复杂,CPU 利用率低 | 占用内存少,切换简单,CPU 利用率高 | 线程占优 |
| 创建销毁、切换 | 创建销毁、切换复杂,速度慢 | 创建销毁、切换简单,速度很快 | 线程占优 |
| 编程、调试 | 编程简单,调试简单 | 编程复杂,调试复杂 | 进程占优 |
| 可靠性 | 进程间不会互相影响 | 一个线程挂掉将导致整个进程挂掉 | 进程占优 |
| 分布式 | 适应于多核、多机分布式;如果一台机器不够,扩展到多台机器比较简单 | 适应于多核分布式 | 进程占优 |
优劣
| 优劣 | 多进程 | 多线程 |
|---|---|---|
| 优点 | 编程、调试简单,可靠性较高 | 创建、销毁、切换速度快,内存、资源占用小 |
| 缺点 | 创建、销毁、切换速度慢,内存、资源占用大 | 编程、调试复杂,可靠性较差 |
选择
- 需要频繁创建销毁的优先用线程
- 需要进行大量计算的优先使用线程
- 强相关的处理用线程,弱相关的处理用进程
- 可能要扩展到多机分布的用进程,多核分布的用线程
- 都满足需求的情况下,用你最熟悉、最拿手的方式
多进程与多线程间的对比、优劣与选择来自:多线程还是多进程的选择及区别
进程状态转换图

Linux 内核的同步方式
原因
在现代操作系统里,同一时间可能有多个内核执行流在执行,因此内核其实象多进程多线程编程一样也需要一些同步机制来同步各执行单元对共享数据的访问。尤其是在多处理器系统上,更需要一些同步机制来同步不同处理器上的执行单元对共享的数据的访问。
同步方式
- 原子操作
- 信号量(semaphore)
- 读写信号量(rw_semaphore)
- 自旋锁(spinlock)
- 大内核锁(BKL,Big Kernel Lock)
- 读写锁(rwlock)
- 大读者锁(brlock-Big Reader Lock)
- 读-拷贝修改(RCU,Read-Copy Update)
- 顺序锁(seqlock)
死锁
原因
- 系统资源不足
- 资源分配不当
- 进程运行推进顺序不合适
产生条件
- 互斥
- 请求和保持
- 不剥夺
- 环路
预防
- 打破互斥条件:改造独占性资源为虚拟资源,大部分资源已无法改造。
- 打破不可抢占条件:当一进程占有一独占性资源后又申请一独占性资源而无法满足,则退出原占有的资源。
- 打破占有且申请条件:采用资源预先分配策略,即进程运行前申请全部资源,满足则运行,不然就等待,这样就不会占有且申请。
- 打破循环等待条件:实现资源有序分配策略,对所有设备实现分类编号,所有进程只能采用按序号递增的形式申请资源。
- 有序资源分配法
- 银行家算法
文件系统
- Windows:FCB 表 + FAT + 位图
- Unix:inode + 混合索引 + 成组链接
主机字节序与网络字节序
主机字节序(CPU 字节序)
概念
主机字节序又叫 CPU 字节序,其不是由操作系统决定的,而是由 CPU 指令集架构决定的。主机字节序分为两种:
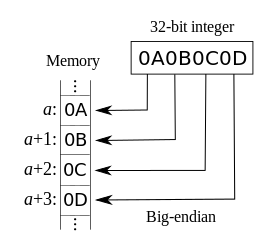
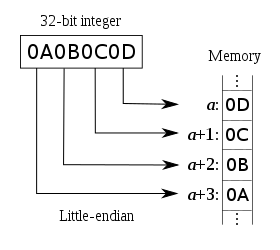
- 大端字节序(Big Endian):高序字节存储在低位地址,低序字节存储在高位地址
- 小端字节序(Little Endian):高序字节存储在高位地址,低序字节存储在低位地址
存储方式
32 位整数 0x12345678 是从起始位置为 0x00 的地址开始存放,则:
| 内存地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 大端 | 12 | 34 | 56 | 78 |
| 小端 | 78 | 56 | 34 | 12 |
大端小端图片
判断大端小端
判断大端小端
可以这样判断自己 CPU 字节序是大端还是小端:
#include <iostream>
using namespace std;
int main()
{
// 方法一
int i = 0x12345678;
if (*((char *)&i) == 0x12)
cout << "big endian" << endl;
else
cout << "little endian" << endl;
// 方法二
union MyUnion {
int a;
char c;
} test;
test.a = 0x12345678;
if (test.c == 0x12)
cout << "big endian" << endl;
else
cout << "little endian" << endl;
return 0;
}各架构处理器的字节序
- x86(Intel、AMD)、MOS Technology 6502、Z80、VAX、PDP-11 等处理器为小端序;
- Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除 V9 外)等处理器为大端序;
- ARM(默认小端序)、PowerPC(除 PowerPC 970 外)、DEC Alpha、SPARC V9、MIPS、PA-RISC 及 IA64 的字节序是可配置的。
网络字节序
网络字节顺序是 TCP/IP 中规定好的一种数据表示格式,它与具体的 CPU 类型、操作系统等无关,从而可以保重数据在不同主机之间传输时能够被正确解释。
网络字节顺序采用:大端(Big Endian)排列方式。
页面置换算法
在地址映射过程中,若在页面中发现所要访问的页面不在内存中,则产生缺页中断。当发生缺页中断时,如果操作系统内存中没有空闲页面,则操作系统必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。而用来选择淘汰哪一页的规则叫做页面置换算法。
分类
- 全局置换:在整个内存空间置换
- 局部置换:在本进程中进行置换
算法
全局:
- 工作集算法
- 缺页率置换算法
局部:
- 最佳置换算法(OPT)
- 先进先出置换算法(FIFO)
- 最近最久未使用(LRU)算法
- 时钟(Clock)置换算法
内存、栈、堆
一般应用程序内存空间有如下区域:
- 栈:由操作系统自动分配释放,存放函数的参数值、局部变量等的值,用于维护函数调用的上下文
- 堆:一般由程序员分配释放,若程序员不释放,程序结束时可能由操作系统回收,用来容纳应用程序动态分配的内存区域
- 可执行文件映像:存储着可执行文件在内存中的映像,由装载器装载是将可执行文件的内存读取或映射到这里
- 保留区:保留区并不是一个单一的内存区域,而是对内存中受到保护而禁止访问的内存区域的总称,如通常 C 语言讲无效指针赋值为 0(NULL),因此 0 地址正常情况下不可能有效的访问数据
栈
栈保存了一个函数调用所需要的维护信息,常被称为堆栈帧(Stack Frame)或活动记录(Activate Record),一般包含以下几方面:
- 函数的返回地址和参数
- 临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量
- 保存上下文:包括函数调用前后需要保持不变的寄存器
堆
堆分配算法:
- 空闲链表(Free List)
- 位图(Bitmap)
- 对象池
堆与栈区别
- 管理方式不同。栈由操作系统自动分配释放,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏;
- 空间大小不同。每个进程拥有的栈的大小要远远小于堆的大小。理论上,程序员可申请的堆大小为虚拟内存的大小,进程栈的大小64bits的Windows默认1MB,64bits的Linux默认10MB;
- 生长方向不同。堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
- 分配方式不同。堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由操作系统进行释放,无需我们手工实现。
- 分配效率不同。栈由操作系统自动分配,会在硬件层级对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是由C/C++提供的库函数或运算符来完成申请与管理,实现机制较为复杂,频繁的内存申请容易产生内存碎片。显然,堆的效率比栈要低得多。
- 存放内容不同。栈存放的内容,函数返回地址、相关参数、局部变量和寄存器内容等。堆,一般情况堆顶使用一个字节的空间来存放堆的大小,而堆中具体存放内容是由程序员来填充的。
- 能否产生碎片。对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题。
“段错误(segment fault)” 或 “非法操作,该内存地址不能 read/write”
典型的非法指针解引用造成的错误。当指针指向一个不允许读写的内存地址,而程序却试图利用指针来读或写该地址时,会出现这个错误。
普遍原因:
- 将指针初始化为 NULL,之后没有给它一个合理的值就开始使用指针
- 没用初始化栈中的指针,指针的值一般会是随机数,之后就直接开始使用指针
编译链接
各平台文件格式
| 平台 | 可执行文件 | 目标文件 | 动态库/共享对象 | 静态库 |
|---|---|---|---|---|
| Windows | exe | obj | dll | lib |
| Unix/Linux | ELF、out | o | so | a |
| Mac | Mach-O | o | dylib、tbd、framework | a、framework |
编译链接过程
- 预编译(预编译器处理如
#include、#define等预编译指令,生成.i或.ii文件) - 编译(编译器进行词法分析、语法分析、语义分析、中间代码生成、目标代码生成、优化,生成
.s文件) - 汇编(汇编器把汇编码翻译成机器码,生成
.o文件) - 链接(连接器进行地址和空间分配、符号决议、重定位,生成
.out文件)
现在版本 GCC 把预编译和编译合成一步,预编译编译程序 cc1、汇编器 as、连接器 ld
MSVC 编译环境,编译器 cl、连接器 link、可执行文件查看器 dumpbin
目标文件
编译器编译源代码后生成的文件叫做目标文件。目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没有经过链接的过程,其中可能有些符号或有些地址还没有被调整。
可执行文件(Windows 的
.exe和 Linux 的ELF)、动态链接库(Windows 的.dll和 Linux 的.so)、静态链接库(Windows 的.lib和 Linux 的.a)都是按照可执行文件格式存储(Windows 按照 PE-COFF,Linux 按照 ELF)
目标文件格式
- Windows 的 PE(Portable Executable),或称为 PE-COFF,
.obj格式 - Linux 的 ELF(Executable Linkable Format),
.o格式 - Intel/Microsoft 的 OMF(Object Module Format)
- Unix 的
a.out格式 - MS-DOS 的
.COM格式
PE 和 ELF 都是 COFF(Common File Format)的变种
目标文件存储结构
| 段 | 功能 |
|---|---|
| File Header | 文件头,描述整个文件的文件属性(包括文件是否可执行、是静态链接或动态连接及入口地址、目标硬件、目标操作系统等) |
| .text section | 代码段,执行语句编译成的机器代码 |
| .data section | 数据段,已初始化的全局变量和局部静态变量 |
| .bss section | BSS 段(Block Started by Symbol),未初始化的全局变量和局部静态变量(因为默认值为 0,所以只是在此预留位置,不占空间) |
| .rodata section | 只读数据段,存放只读数据,一般是程序里面的只读变量(如 const 修饰的变量)和字符串常量 |
| .comment section | 注释信息段,存放编译器版本信息 |
| .note.GNU-stack section | 堆栈提示段 |
其他段略
链接的接口————符号
在链接中,目标文件之间相互拼合实际上是目标文件之间对地址的引用,即对函数和变量的地址的引用。我们将函数和变量统称为符号(Symbol),函数名或变量名就是符号名(Symbol Name)。
如下符号表(Symbol Table):
| Symbol(符号名) | Symbol Value (地址) |
|---|---|
| main | 0x100 |
| Add | 0x123 |
| ... | ... |
Linux 的共享库(Shared Library)
Linux 下的共享库就是普通的 ELF 共享对象。
共享库版本更新应该保证二进制接口 ABI(Application Binary Interface)的兼容
命名
libname.so.x.y.z
- x:主版本号,不同主版本号的库之间不兼容,需要重新编译
- y:次版本号,高版本号向后兼容低版本号
- z:发布版本号,不对接口进行更改,完全兼容
路径
大部分包括 Linux 在内的开源系统遵循 FHS(File Hierarchy Standard)的标准,这标准规定了系统文件如何存放,包括各个目录结构、组织和作用。
/lib:存放系统最关键和最基础的共享库,如动态链接器、C 语言运行库、数学库等/usr/lib:存放非系统运行时所需要的关键性的库,主要是开发库/usr/local/lib:存放跟操作系统本身并不十分相关的库,主要是一些第三方应用程序的库
动态链接器会在
/lib、/usr/lib和由/etc/ld.so.conf配置文件指定的,目录中查找共享库
环境变量
LD_LIBRARY_PATH:临时改变某个应用程序的共享库查找路径,而不会影响其他应用程序LD_PRELOAD:指定预先装载的一些共享库甚至是目标文件LD_DEBUG:打开动态链接器的调试功能
so 共享库的编写
使用 CLion 编写共享库
创建一个名为 MySharedLib 的共享库
CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(MySharedLib)
set(CMAKE_CXX_STANDARD 11)
add_library(MySharedLib SHARED library.cpp library.h)library.h
#ifndef MYSHAREDLIB_LIBRARY_H
#define MYSHAREDLIB_LIBRARY_H
// 打印 Hello World!
void hello();
// 使用可变模版参数求和
template <typename T>
T sum(T t)
{
return t;
}
template <typename T, typename ...Types>
T sum(T first, Types ... rest)
{
return first + sum<T>(rest...);
}
#endiflibrary.cpp
#include <iostream>
#include "library.h"
void hello() {
std::cout << "Hello, World!" << std::endl;
}so 共享库的使用(被可执行项目调用)
使用 CLion 调用共享库
创建一个名为 TestSharedLib 的可执行项目
CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(TestSharedLib)
# C++11 编译
set(CMAKE_CXX_STANDARD 11)
# 头文件路径
set(INC_DIR /home/xx/code/clion/MySharedLib)
# 库文件路径
set(LIB_DIR /home/xx/code/clion/MySharedLib/cmake-build-debug)
include_directories(${INC_DIR})
link_directories(${LIB_DIR})
link_libraries(MySharedLib)
add_executable(TestSharedLib main.cpp)
# 链接 MySharedLib 库
target_link_libraries(TestSharedLib MySharedLib)main.cpp
#include <iostream>
#include "library.h"
using std::cout;
using std::endl;
int main() {
hello();
cout << "1 + 2 = " << sum(1,2) << endl;
cout << "1 + 2 + 3 = " << sum(1,2,3) << endl;
return 0;
}执行结果
Hello, World!
1 + 2 = 3
1 + 2 + 3 = 6Windows 应用程序入口函数
- GUI(Graphical User Interface)应用,链接器选项:
/SUBSYSTEM:WINDOWS - CUI(Console User Interface)应用,链接器选项:
/SUBSYSTEM:CONSOLE
_tWinMain 与 _tmain 函数声明
Int WINAPI _tWinMain(
HINSTANCE hInstanceExe,
HINSTANCE,
PTSTR pszCmdLine,
int nCmdShow);
int _tmain(
int argc,
TCHAR *argv[],
TCHAR *envp[]);| 应用程序类型 | 入口点函数 | 嵌入可执行文件的启动函数 |
|---|---|---|
| 处理ANSI字符(串)的GUI应用程序 | _tWinMain(WinMain) | WinMainCRTSartup |
| 处理Unicode字符(串)的GUI应用程序 | _tWinMain(wWinMain) | wWinMainCRTSartup |
| 处理ANSI字符(串)的CUI应用程序 | _tmain(Main) | mainCRTSartup |
| 处理Unicode字符(串)的CUI应用程序 | _tmain(wMain) | wmainCRTSartup |
| 动态链接库(Dynamic-Link Library) | DllMain | _DllMainCRTStartup |
Windows 的动态链接库(Dynamic-Link Library)
部分知识点来自《Windows 核心编程(第五版)》
用处
- 扩展了应用程序的特性
- 简化了项目管理
- 有助于节省内存
- 促进了资源的共享
- 促进了本地化
- 有助于解决平台间的差异
- 可以用于特殊目的
注意
- 创建 DLL,事实上是在创建可供一个可执行模块调用的函数
- 当一个模块提供一个内存分配函数(malloc、new)的时候,它必须同时提供另一个内存释放函数(free、delete)
- 在使用 C 和 C++ 混编的时候,要使用 extern "C" 修饰符
- 一个 DLL 可以导出函数、变量(避免导出)、C++ 类(导出导入需要同编译器,否则避免导出)
- DLL 模块:cpp 文件中的 __declspec(dllexport) 写在 include 头文件之前
- 调用 DLL 的可执行模块:cpp 文件的 __declspec(dllimport) 之前不应该定义 MYLIBAPI
加载 Windows 程序的搜索顺序
- 包含可执行文件的目录
- Windows 的系统目录,可以通过 GetSystemDirectory 得到
- 16 位的系统目录,即 Windows 目录中的 System 子目录
- Windows 目录,可以通过 GetWindowsDirectory 得到
- 进程的当前目录
- PATH 环境变量中所列出的目录
DLL 入口函数
DllMain 函数
BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved)
{
switch(fdwReason)
{
case DLL_PROCESS_ATTACH:
// 第一次将一个DLL映射到进程地址空间时调用
// The DLL is being mapped into the process' address space.
break;
case DLL_THREAD_ATTACH:
// 当进程创建一个线程的时候,用于告诉DLL执行与线程相关的初始化(非主线程执行)
// A thread is bing created.
break;
case DLL_THREAD_DETACH:
// 系统调用 ExitThread 线程退出前,即将终止的线程通过告诉DLL执行与线程相关的清理
// A thread is exiting cleanly.
break;
case DLL_PROCESS_DETACH:
// 将一个DLL从进程的地址空间时调用
// The DLL is being unmapped from the process' address space.
break;
}
return (TRUE); // Used only for DLL_PROCESS_ATTACH
}载入卸载库
LoadLibrary、LoadLibraryExA、LoadPackagedLibrary、FreeLibrary、FreeLibraryAndExitThread 函数声明
// 载入库
HMODULE WINAPI LoadLibrary(
_In_ LPCTSTR lpFileName
);
HMODULE LoadLibraryExA(
LPCSTR lpLibFileName,
HANDLE hFile,
DWORD dwFlags
);
// 若要在通用 Windows 平台(UWP)应用中加载 Win32 DLL,需要调用 LoadPackagedLibrary,而不是 LoadLibrary 或 LoadLibraryEx
HMODULE LoadPackagedLibrary(
LPCWSTR lpwLibFileName,
DWORD Reserved
);
// 卸载库
BOOL WINAPI FreeLibrary(
_In_ HMODULE hModule
);
// 卸载库和退出线程
VOID WINAPI FreeLibraryAndExitThread(
_In_ HMODULE hModule,
_In_ DWORD dwExitCode
);显示地链接到导出符号
GetProcAddress 函数声明
FARPROC GetProcAddress(
HMODULE hInstDll,
PCSTR pszSymbolName // 只能接受 ANSI 字符串,不能是 Unicode
);DumpBin.exe 查看 DLL 信息
在 VS 的开发人员命令提示符 使用 DumpBin.exe 可查看 DLL 库的导出段(导出的变量、函数、类名的符号)、相对虚拟地址(RVA,relative virtual address)。如:
DUMPBIN -exports D:\mydll.dllLoadLibrary 与 FreeLibrary 流程图
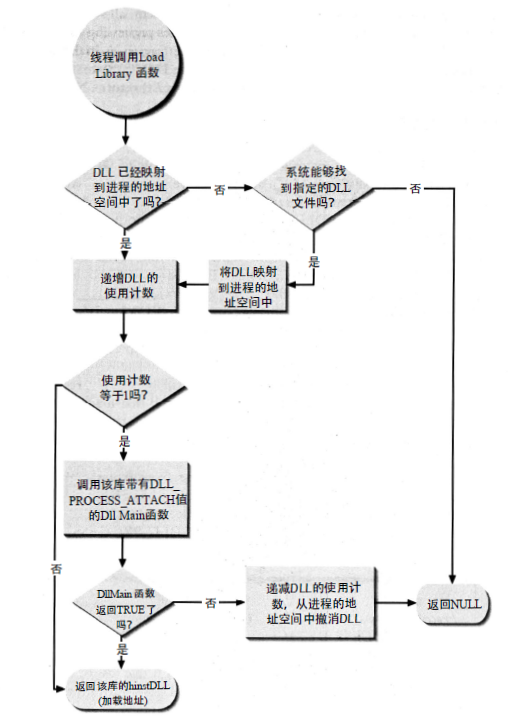
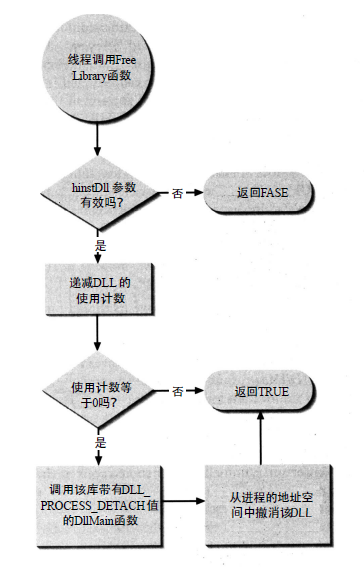
LoadLibrary 与 FreeLibrary 流程图
LoadLibrary
FreeLibrary
DLL 库的编写(导出一个 DLL 模块)
DLL 库的编写(导出一个 DLL 模块)
DLL 头文件
// MyLib.h
#ifdef MYLIBAPI
// MYLIBAPI 应该在全部 DLL 源文件的 include "Mylib.h" 之前被定义
// 全部函数/变量正在被导出
#else
// 这个头文件被一个exe源代码模块包含,意味着全部函数/变量被导入
#define MYLIBAPI extern "C" __declspec(dllimport)
#endif
// 这里定义任何的数据结构和符号
// 定义导出的变量(避免导出变量)
MYLIBAPI int g_nResult;
// 定义导出函数原型
MYLIBAPI int Add(int nLeft, int nRight);DLL 源文件
// MyLibFile1.cpp
// 包含标准Windows和C运行时头文件
#include <windows.h>
// DLL源码文件导出的函数和变量
#define MYLIBAPI extern "C" __declspec(dllexport)
// 包含导出的数据结构、符号、函数、变量
#include "MyLib.h"
// 将此DLL源代码文件的代码放在此处
int g_nResult;
int Add(int nLeft, int nRight)
{
g_nResult = nLeft + nRight;
return g_nResult;
}DLL 库的使用(运行时动态链接 DLL)
DLL 库的使用(运行时动态链接 DLL)
// A simple program that uses LoadLibrary and
// GetProcAddress to access myPuts from Myputs.dll.
#include <windows.h>
#include <stdio.h>
typedef int (__cdecl *MYPROC)(LPWSTR);
int main( void )
{
HINSTANCE hinstLib;
MYPROC ProcAdd;
BOOL fFreeResult, fRunTimeLinkSuccess = FALSE;
// Get a handle to the DLL module.
hinstLib = LoadLibrary(TEXT("MyPuts.dll"));
// If the handle is valid, try to get the function address.
if (hinstLib != NULL)
{
ProcAdd = (MYPROC) GetProcAddress(hinstLib, "myPuts");
// If the function address is valid, call the function.
if (NULL != ProcAdd)
{
fRunTimeLinkSuccess = TRUE;
(ProcAdd) (L"Message sent to the DLL function\n");
}
// Free the DLL module.
fFreeResult = FreeLibrary(hinstLib);
}
// If unable to call the DLL function, use an alternative.
if (! fRunTimeLinkSuccess)
printf("Message printed from executable\n");
return 0;
}运行库(Runtime Library)
典型程序运行步骤
- 操作系统创建进程,把控制权交给程序的入口(往往是运行库中的某个入口函数)
- 入口函数对运行库和程序运行环境进行初始化(包括堆、I/O、线程、全局变量构造等等)。
- 入口函数初始化后,调用 main 函数,正式开始执行程序主体部分。
- main 函数执行完毕后,返回到入口函数进行清理工作(包括全局变量析构、堆销毁、关闭I/O等),然后进行系统调用结束进程。
一个程序的 I/O 指代程序与外界的交互,包括文件、管程、网络、命令行、信号等。更广义地讲,I/O 指代操作系统理解为 “文件” 的事物。
glibc 入口
_start -> __libc_start_main -> exit -> _exit
其中 main(argc, argv, __environ) 函数在 __libc_start_main 里执行。
MSVC CRT 入口
int mainCRTStartup(void)
执行如下操作:
- 初始化和 OS 版本有关的全局变量。
- 初始化堆。
- 初始化 I/O。
- 获取命令行参数和环境变量。
- 初始化 C 库的一些数据。
- 调用 main 并记录返回值。
- 检查错误并将 main 的返回值返回。
C 语言运行库(CRT)
大致包含如下功能:
- 启动与退出:包括入口函数及入口函数所依赖的其他函数等。
- 标准函数:有 C 语言标准规定的C语言标准库所拥有的函数实现。
- I/O:I/O 功能的封装和实现。
- 堆:堆的封装和实现。
- 语言实现:语言中一些特殊功能的实现。
- 调试:实现调试功能的代码。
C语言标准库(ANSI C)
包含:
- 标准输入输出(stdio.h)
- 文件操作(stdio.h)
- 字符操作(ctype.h)
- 字符串操作(string.h)
- 数学函数(math.h)
- 资源管理(stdlib.h)
- 格式转换(stdlib.h)
- 时间/日期(time.h)
- 断言(assert.h)
- 各种类型上的常数(limits.h & float.h)
- 变长参数(stdarg.h)
- 非局部跳转(setjmp.h)
设计模式
各大设计模式例子参考:CSDN专栏 . C++ 设计模式 系列博文
单例模式
抽象工厂模式
适配器模式
桥接模式
观察者模式
设计模式的六大原则
- 单一职责原则(SRP,Single Responsibility Principle)
- 里氏替换原则(LSP,Liskov Substitution Principle)
- 依赖倒置原则(DIP,Dependence Inversion Principle)
- 接口隔离原则(ISP,Interface Segregation Principle)
- 迪米特法则(LoD,Law of Demeter)
- 开放封闭原则(OCP,Open Close Principle)
数据库
本节部分知识点来自《数据库系统概论(第 5 版)》
基本概念
- 数据(data):描述事物的符号记录称为数据。
- 数据库(DataBase,DB):是长期存储在计算机内、有组织的、可共享的大量数据的集合,具有永久存储、有组织、可共享三个基本特点。
- 数据库管理系统(DataBase Management System,DBMS):是位于用户与操作系统之间的一层数据管理软件。
- 数据库系统(DataBase System,DBS):是有数据库、数据库管理系统(及其应用开发工具)、应用程序和数据库管理员(DataBase Administrator DBA)组成的存储、管理、处理和维护数据的系统。
- 实体(entity):客观存在并可相互区别的事物称为实体。
- 属性(attribute):实体所具有的某一特性称为属性。
- 码(key):唯一标识实体的属性集称为码。
- 实体型(entity type):用实体名及其属性名集合来抽象和刻画同类实体,称为实体型。
- 实体集(entity set):同一实体型的集合称为实体集。
- 联系(relationship):实体之间的联系通常是指不同实体集之间的联系。
- 模式(schema):模式也称逻辑模式,是数据库全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
- 外模式(external schema):外模式也称子模式(subschema)或用户模式,它是数据库用户(包括应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。
- 内模式(internal schema):内模式也称为存储模式(storage schema),一个数据库只有一个内模式。他是数据物理结构和存储方式的描述,是数据库在数据库内部的组织方式。
常用数据模型
- 层次模型(hierarchical model)
- 网状模型(network model)
- 关系模型(relational model)
- 关系(relation):一个关系对应通常说的一张表
- 元组(tuple):表中的一行即为一个元组
- 属性(attribute):表中的一列即为一个属性
- 码(key):表中可以唯一确定一个元组的某个属性组
- 域(domain):一组具有相同数据类型的值的集合
- 分量:元组中的一个属性值
- 关系模式:对关系的描述,一般表示为
关系名(属性1, 属性2, ..., 属性n)
- 面向对象数据模型(object oriented data model)
- 对象关系数据模型(object relational data model)
- 半结构化数据模型(semistructure data model)
常用 SQL 操作
SQL 教程:SQL 教程
SQL 语法教程:runoob . SQL 教程
关系型数据库
- 基本关系操作:查询(选择、投影、连接(等值连接、自然连接、外连接(左外连接、右外连接))、除、并、差、交、笛卡尔积等)、插入、删除、修改
- 关系模型中的三类完整性约束:实体完整性、参照完整性、用户定义的完整性
索引
- 数据库索引:顺序索引、B+ 树索引、hash 索引
- MySQL 索引背后的数据结构及算法原理
数据库完整性
- 数据库的完整性是指数据的正确性和相容性。
- 完整性:为了防止数据库中存在不符合语义(不正确)的数据。
- 安全性:为了保护数据库防止恶意破坏和非法存取。
- 触发器:是用户定义在关系表中的一类由事件驱动的特殊过程。
关系数据理论
- 数据依赖是一个关系内部属性与属性之间的一种约束关系,是通过属性间值的相等与否体现出来的数据间相关联系。
- 最重要的数据依赖:函数依赖、多值依赖。
范式
- 第一范式(1NF):属性(字段)是最小单位不可再分。
- 第二范式(2NF):满足 1NF,每个非主属性完全依赖于主键(消除 1NF 非主属性对码的部分函数依赖)。
- 第三范式(3NF):满足 2NF,任何非主属性不依赖于其他非主属性(消除 2NF 主属性对码的传递函数依赖)。
- 鲍依斯-科得范式(BCNF):满足 3NF,任何非主属性不能对主键子集依赖(消除 3NF 主属性对码的部分和传递函数依赖)。
- 第四范式(4NF):满足 3NF,属性之间不能有非平凡且非函数依赖的多值依赖(消除 3NF 非平凡且非函数依赖的多值依赖)。
数据库恢复
- 事务:是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。
- 事物的 ACID 特性:原子性、一致性、隔离性、持续性。
- 恢复的实现技术:建立冗余数据 -> 利用冗余数据实施数据库恢复。
- 建立冗余数据常用技术:数据转储(动态海量转储、动态增量转储、静态海量转储、静态增量转储)、登记日志文件。
并发控制
- 事务是并发控制的基本单位。
- 并发操作带来的数据不一致性包括:丢失修改、不可重复读、读 “脏” 数据。
- 并发控制主要技术:封锁、时间戳、乐观控制法、多版本并发控制等。
- 基本封锁类型:排他锁(X 锁 / 写锁)、共享锁(S 锁 / 读锁)。
- 活锁死锁:
- 活锁:事务永远处于等待状态,可通过先来先服务的策略避免。
- 死锁:事物永远不能结束
- 预防:一次封锁法、顺序封锁法;
- 诊断:超时法、等待图法;
- 解除:撤销处理死锁代价最小的事务,并释放此事务的所有的锁,使其他事务得以继续运行下去。
- 可串行化调度:多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行这些事务时的结果相同。可串行性时并发事务正确调度的准则。
MySQL主从备份原理
简单的说就是把 一个服务器上执行过的sql语句在别的服务器上也重复执行一遍, 这样只要两个数据库的初态是一样的,那么它们就能一直同步。当然这种复制和重复都是mysql自动实现的,我们只需要配置即可。

上图中有两个服务器,演示了从一个主服务器(master)把数据同步到从服务器(slave)的过程。
对于一个mysql服务器,一般有两个线程来负责复制和被复制。当开启复制这个开关之后(start slave)
- 作为主服务器Master,会把自己的每一次改动都记录到 二进制日志 Binarylog 中。 (从服务器会负责来读取这个log,然后在自己那里再执行一遍。)
- 作为从服务器Slave,会用master上的账号登陆到master上,去读取master的Binarylog, 然后写入到自己的中继日志Relaylog,然后自己的sql线程会负责读取这个中继日志,并执行一遍。到这里主服务器上的更改就同步到从服务器上了。