引言
之前分享过“以太坊状态树state的修剪流程”,讲述了上层清理trie中数据库里面的数据的条件以及时机。这篇再简单介绍一下trie对应的数据库的相关操作。所以后面说的数据库,如果没做特别说明,都是trie对应的数据库。
Trie 的 Hash 与 Commit
以太坊的PoW共识算法来说,需要stateRoot,txHash以及其他字段才能够开始挖矿。其中stateRoot就是Trie计算出来的根哈希。而影响stateRoot就是一笔一笔的交易(txHash体现)。事实上,矿工为了获取最大交易费会尽量打包更多的交易,所以每隔3s(默认设置)就会从交易池中获取交易执行然后算出stateRoot重新挖矿。按照以太坊15s出一个块,假设有个矿工是在第10s找到答案,而且每次打包的交易都不一样,那么这个矿工已经在本地生成了10 / 3 + 1 == 4个合法的区块。其中3个未找到答案的区块,最后1个是找到答案的区块。
很明显,这4个区块,都需要stateRoot即trie计算出来根哈希来进行计算,而最后一个找到答案的区块对应的trie,需要保存到数据库方便后续使用,修剪,持久化到leveldb数据库中。计算根哈希的操作,对应trie的Hash计算。而提交到数据库的操作,则是对应trie的Commit。其中Commit包含了Hash计算的调用。下面是精简过后的代码:
func (t *Trie) Hash() common.Hash {
hash, cached, _ := t.hashRoot()
t.root = cached
return common.BytesToHash(hash.(hashNode))
}
func (t *Trie) Commit(onleaf LeafCallback) (common.Hash, int, error) {
......
rootHash := t.Hash()
......
newRoot, committed, err := h.Commit(t.root, t.db)
......
}所以后续对数据库的操作,都是提交到数据库的数据。至于前面3棵trie,由于没有提交到数据库,它所对应的内存由go垃圾回收机制管理。
cachedNode 缓存节点
cachedNode 是将trie里面的节点fullNode,shortNode等提交到数据库时,将其进行一个包裹,方便后续的提交,修剪等操作。对应的数据结构如下所示:
type cachedNode struct {
node node // Cached collapsed trie node, or raw rlp data
size uint16 // Byte size of the useful cached data
parents uint32 // Number of live nodes referencing this one
children map[common.Hash]uint16 // External children referenced by this node
flushPrev common.Hash // Previous node in the flush-list
flushNext common.Hash // Next node in the flush-list
}先对各个字段的含义大概如下介绍,后续分析修剪,提交到leveldb的时候再结合含义说明。
- node: trie里面的fullNode,shortNode等节点(其实做了一个简单包裹)。
- size: trie里面的fullNode,shortNode等节点所占用的内存,比如一个哈希节点就是32字节。
- parents: 有多少个节点引用了当前节点。
- children: 当前节点引用某个孩子的次数。
- flushPrev: 按照顺序提交到数据库的当前节点的前一个cacheNode。
- flushNext: 按照顺序提交到数据库的当前节点的后一个cacheNode。
用一个图来说,大概在数据库里面会形成一个如下所示的关系图(其中child1, child2应该也在flush里面,不太好画就没画了):
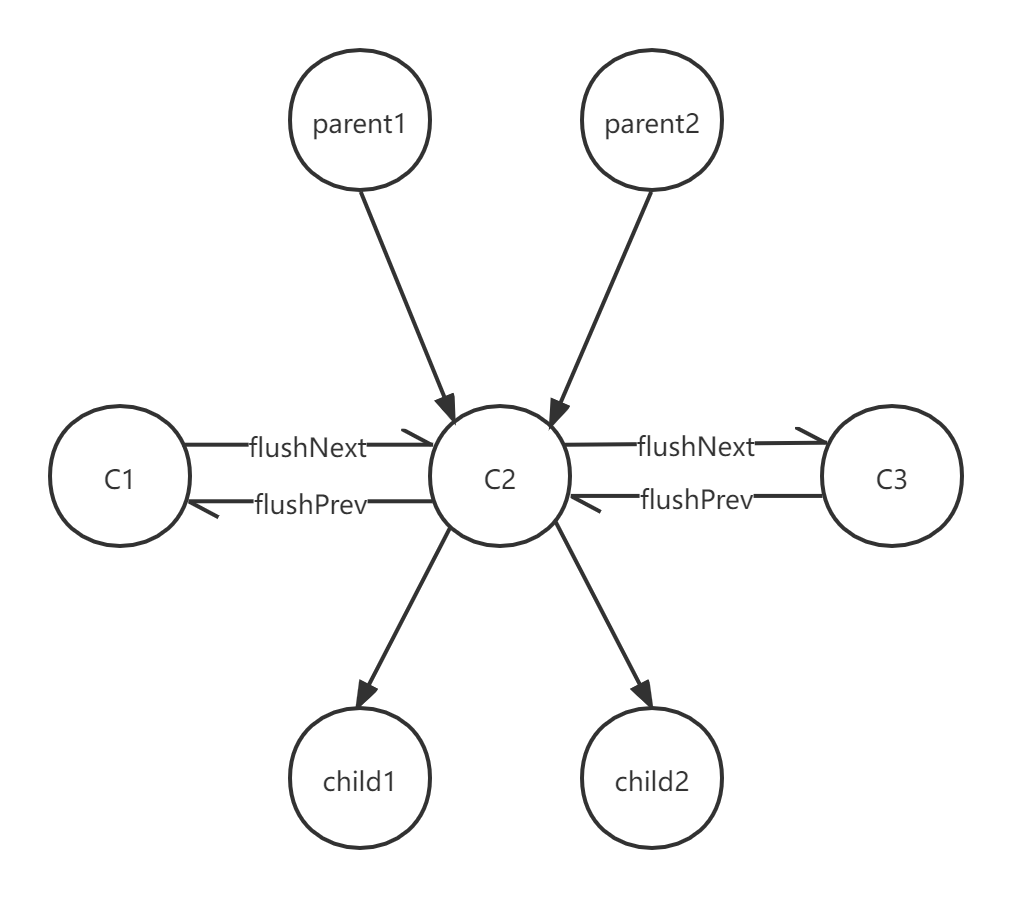
Database Trie对应数据库
这个就是trie对应的数据库。
type Database struct {
diskdb ethdb.KeyValueStore // Persistent storage for matured trie nodes
cleans *fastcache.Cache // GC friendly memory cache of clean node RLPs
dirties map[common.Hash]*cachedNode // Data and references relationships of dirty trie nodes
oldest common.Hash // Oldest tracked node, flush-list head
newest common.Hash // Newest tracked node, flush-list tail
preimages map[common.Hash][]byte // Preimages of nodes from the secure trie
gctime time.Duration // Time spent on garbage collection since last commit
gcnodes uint64 // Nodes garbage collected since last commit
gcsize common.StorageSize // Data storage garbage collected since last commit
flushtime time.Duration // Time spent on data flushing since last commit
flushnodes uint64 // Nodes flushed since last commit
flushsize common.StorageSize // Data storage flushed since last commit
dirtiesSize common.StorageSize // Storage size of the dirty node cache (exc. metadata)
childrenSize common.StorageSize // Storage size of the external children tracking
preimagesSize common.StorageSize // Storage size of the preimages cache
lock sync.RWMutex
}依次对关键字段做个简单说明:
- diskdb:将最终需要提交的数据最终提交到leveldb持久化存储。
- dirties:上面所有提交的cachedNode都保存在这个map里面。
- oldest:最早提交到dirties里面的cachedNode节点。对应上图的c1。
- newest:最新提交到dirties里面的cachedNode节点。对应上图的c3。
- gcnodes:最后一次提交回收的垃圾节点数目。
- gcsize:最后一次提交回收的垃圾节点所占用的内存。
- flushtime:最后一次提交花费时间。
- flushnodes:最后一次提交提交到leveldb的节点数目。
- flushsize:最后一次提交提交到leveldb所占用的内存。
- dirtiesSize:已缓存的节点总共占用的容量。
- preimagesSize:SecureTrie中key-value对占用容量。
insert 提交到数据库
func (db *Database) insert(hash common.Hash, size int, node node) {
// If the node's already cached, skip
if _, ok := db.dirties[hash]; ok {
return
}
memcacheDirtyWriteMeter.Mark(int64(size))
// Create the cached entry for this node
entry := &cachedNode{
node: simplifyNode(node),
size: uint16(size),
flushPrev: db.newest,
}
entry.forChilds(func(child common.Hash) {
if c := db.dirties[child]; c != nil {
c.parents++
}
})
db.dirties[hash] = entry
// Update the flush-list endpoints
if db.oldest == (common.Hash{}) {
db.oldest, db.newest = hash, hash
} else {
db.dirties[db.newest].flushNext, db.newest = hash, hash // c1 <--> c2 ---> newC
}
db.dirtiesSize += common.StorageSize(common.HashLength + entry.size)
}上面提到的trie的Commit操作,最终会调用到这里。主要是将所有子节点的parents+1然后加到map容器dirties。关于flush的指向,由于是最新加入的节点,所以初始化cachedNode的时候将它自己的上一个指向之前最新的一个(c1 <--> c2 <--- newC),而最新的后一个指向当前加入的节点(c1 <--> c2 ---> newC)。当然,如果他是第一个提交数据库的节点,那么初始化一下数据库最旧与最新的指向即可。
Cap 强制提交使之内存占用降低
为了说明问题,只保留函数关键逻辑。
func (db *Database) Cap(limit common.StorageSize) error {
flushPreimages := db.preimagesSize > 4*1024*1024
if flushPreimages {
......
rawdb.WritePreimages(batch, db.preimages)
.....
}
oldest := db.oldest
for size > limit && oldest != (common.Hash{}) {
node := db.dirties[oldest]
rawdb.WriteTrieNode(batch, oldest, node.rlp())
......
size -= common.StorageSize(common.HashLength + int(node.size) + cachedNodeSize)
......
oldest = node.flushNext
}
......
for db.oldest != oldest {
node := db.dirties[db.oldest]
delete(db.dirties, db.oldest)
db.oldest = node.flushNext
......
}
if db.oldest != (common.Hash{}) {
db.dirties[db.oldest].flushPrev = common.Hash{}
}
......
}在分析state的修剪流程时候,提到当trie对应的数据库超过256M的时候,系统就会调用一次将数据提交到leveldb使之数据库中占用的内存降低到256M以下。上层正式调用的这个Cap函数。那么需要提交哪些数据呢?由于Preimages数据量不会太多,直接全部提交。而对于节点数据,则从最旧的节点开始提交,直到数据库内存达到符合要求的值。提交完毕,将节点从dirties里面删除,并更新数据库最旧的提交的指向。
reference 节点引用
func (db *Database) reference(child common.Hash, parent common.Hash) {
// If the node does not exist, it's a node pulled from disk, skip
node, ok := db.dirties[child]
if !ok {
return
}
// If the reference already exists, only duplicate for roots
if db.dirties[parent].children == nil {
db.dirties[parent].children = make(map[common.Hash]uint16)
db.childrenSize += cachedNodeChildrenSize
} else if _, ok = db.dirties[parent].children[child]; ok && parent != (common.Hash{}) {
return
}
node.parents++
db.dirties[parent].children[child]++
if db.dirties[parent].children[child] == 1 {
db.childrenSize += common.HashLength + 2 // uint16 counter
}
}节点的引用总结来说有两个地方调用到:
一个是生成区块的时候:triedb.Reference(root, common.Hash{}),注意,此时的入参parent是一个空哈希(为了保证db.dirties存在空哈希对应的cacheNode,在构建database的时候会默认创建)。
二是整颗世界树提交的时候合约:s.db.TrieDB().Reference(account.Root, parent)
引用逻辑很简单,就是看传进来的父亲有没有引用孩子,如果没有引用孩子,那么就引用一次。
其中有个判断ok = db.dirties[parent].children[child]; ok && parent != (common.Hash{})需要详细分析一下。意思就是,如果某个父亲对这个孩子引用过一次,而且这个父节点不是个空哈希,那么直接返回。对于父节点是空哈希的上面我们分析过,是生成区块的时候对整合状态树进行引用。而代码逻辑是允许继续引用的。这也很好理解,上面的代码是在blockchain模块调用的,如果其他模块有需要,我也可以对这整棵树进行引用,所以允许多次引用。但是对于合约也就是说parent不为空的情况,一个父节点是最多是只有一个孩子的,所以就直接返回了。
dereference 节点解引用
func (db *Database) dereference(child common.Hash, parent common.Hash) {
node := db.dirties[parent]
if node.children != nil && node.children[child] > 0 {
node.children[child]--
if node.children[child] == 0 {
delete(node.children, child)
db.childrenSize -= (common.HashLength + 2) // uint16 counter
}
}
// If the child does not exist, it's a previously committed node.
node, ok := db.dirties[child]
if !ok {
return
}
// If there are no more references to the child, delete it and cascade
if node.parents > 0 {
node.parents--
}
if node.parents == 0 {
// Remove the node from the flush-list
switch child {
case db.oldest:
db.oldest = node.flushNext
db.dirties[node.flushNext].flushPrev = common.Hash{}
case db.newest:
db.newest = node.flushPrev
db.dirties[node.flushPrev].flushNext = common.Hash{}
default:
db.dirties[node.flushPrev].flushNext = node.flushNext
db.dirties[node.flushNext].flushPrev = node.flushPrev
}
// Dereference all children and delete the node
node.forChilds(func(hash common.Hash) {
db.dereference(hash, child)
})
delete(db.dirties, child)
db.dirtiesSize -= common.StorageSize(common.HashLength + int(node.size))
if node.children != nil {
db.childrenSize -= cachedNodeChildrenSize
}
}
}解引用只对整颗状态树,不会对合约进行解引用。从代码逻辑来看,传进来的parent写的是空哈希。这也好理解,因为合约是一颗小的trie存在整颗状态树里面。解引用的大概逻辑是:
- 父节点对子节点的引用数-1,如果他对这个子节点的引用计数变为了0,那么直接从子节点列表中将其删除(此时节点还在内存中)
- 找到对应的子节点,将它引用它的父节点的数目-1。如果引用它父节点的数目变为0,说明没有任何节点引用他了。这个节点有可能在数据库中是最旧的,最新的,中间的节点,根据这三种情况刷新刷新database它的更新列表。然后继续解引用它的子节点,最后从内存中释放这个节点。
下面,以一个简单的示例来说明解引用的过程
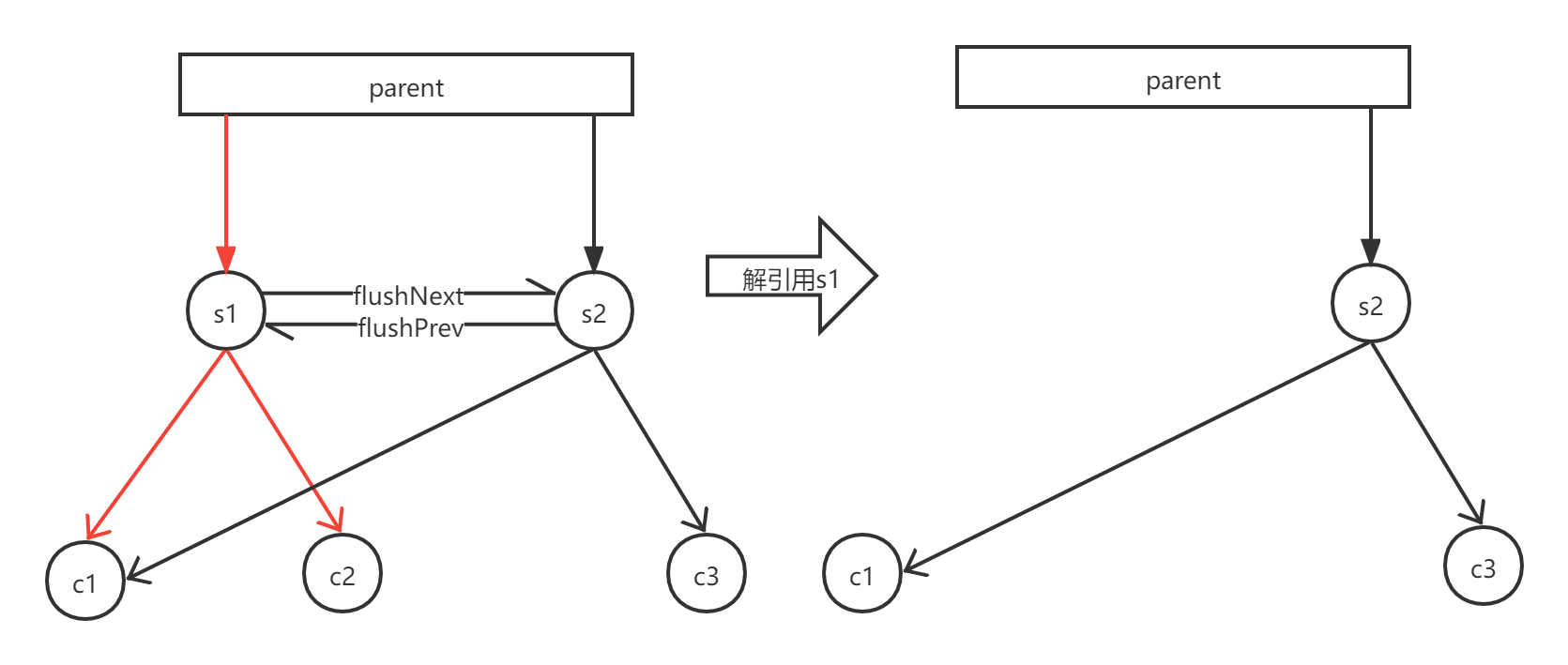
以解引用s1节点为例。假设parent已存在节点s1, s2。parent对s1, s2的引用次数均为1。
调用dereference对s1进行解引用。此时由于parent对s1节点引用次数为1,减去1之后引用次数为0。所以将s1从parent.children中删除。
继续对s1的子节点进行解应用。首先对c1节点解引用,将c1的父节点引用计数-1。由于c1有两个节点引用了,解引用之后c1还有1个父节点引用了,所以继续留在内存中。紧接着对c2节点解引用,将c2节点的父节点引用计数-1,变为了0,此时没有任何父节点对它进行引用,从数据库中删除。操作之后,数据库删除s1, c2,保留s2, c1, c3.